Maybe it’s a byproduct of Google search getting progressively worse for narrow outcome searches or the fact that it may not yet exist – but I couldn’t find any JSON templates for custom calls to ChatGPT.
For any low/no-coders using N8N to prototype AI wrappers or just play with it’s call capabilities you might you may want to play with more settings than the managed call environment offers and I want to make that transition easier for you with this JSON template that covers all of the main settings and configs you’d want to pass or really experiment with.
Managed Call vs Custom Call
N8N and other no/low-code platforms offer managed ChatGPT flows that make it easy to message models but as your skillset grows and maybe your curiosity when it comes temperature and p value settings – you’ll find these managed calls won’t work.
In addition to fine-tuning settings, everything you’ll be using in your mini-app will be in JSON payloads so why not have your call in JSON as well?
ChatGPT Custom Call Template
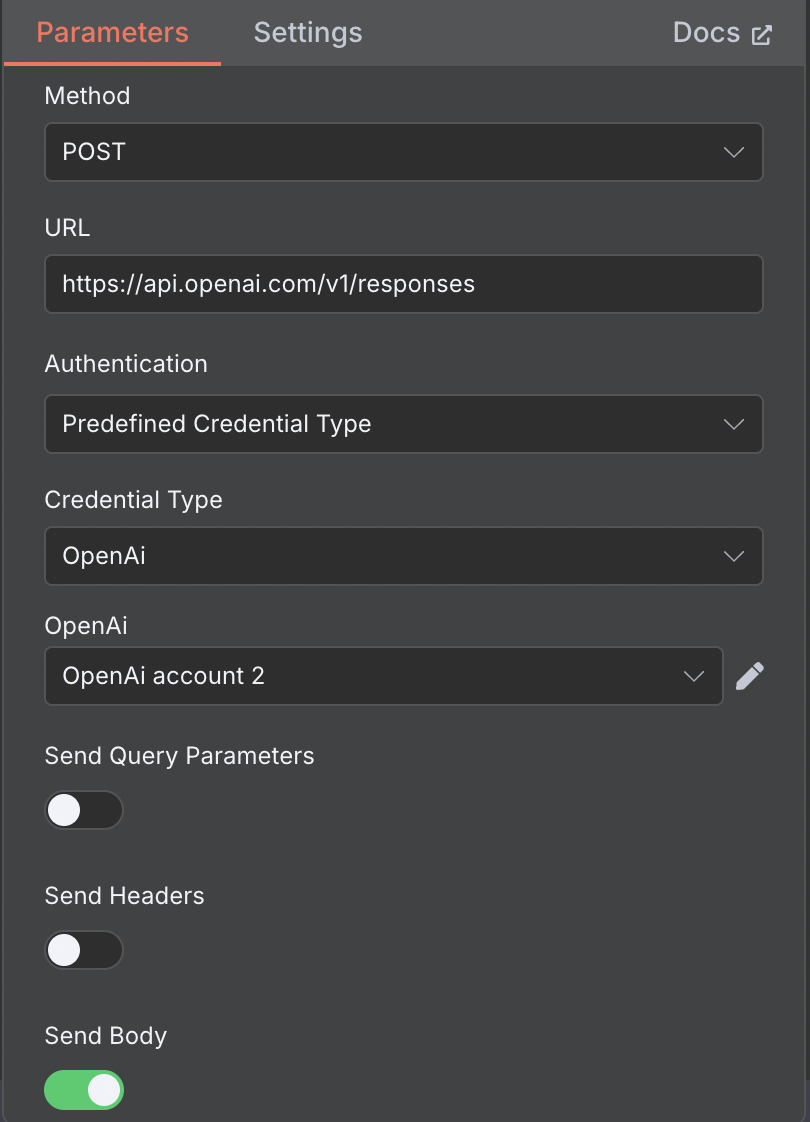
To set this up:
- Create a HTTP Request step in your flow and link it
- Set Method to POST
- Set URL to https://api.openai.com/v1/responses
- If you’re using managed calls, you would have already setup your authentication. You can pass your key as part of a custom call but for this example let’s keep things simple
- ‘Send Query Parameters’ / ‘Send Headers’ should be set to OFF
- ‘Send Body’ set to ON
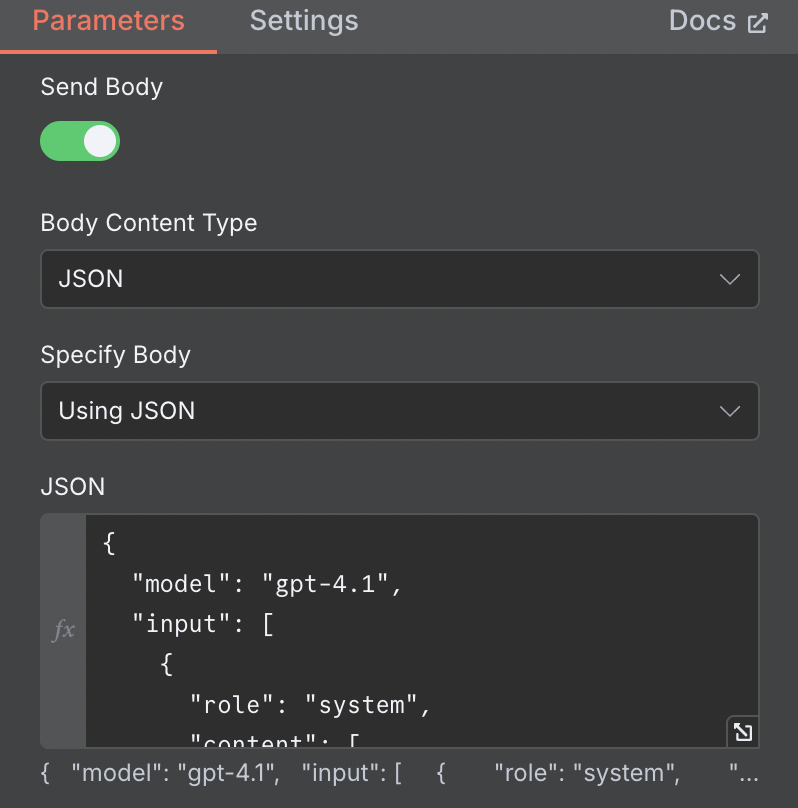
7. Set Body Content Type to JSON
8. Set Specify Body to JSON
9. Customize and Paste this template
{
"model": "gpt-4.1",
"input": [
{
"role": "system",
"content": [
{
"type": "input_text",
"text": "System Prompt Text"
}
]
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "User Prompt Text"
}
]
}
],
"text": {
"format": {
"type": "text"
}
},
"reasoning": {},
"tools": [
{
"type": "web_search_preview",
"user_location": {
"type": "approximate",
"country": "US"
},
"search_context_size": "medium"
}
],
"temperature": 0,
"max_output_tokens": 2048,
"top_p": 0,
"store": true
}So what are we setting in the above? Let’s talk through it:
- System Prompt
- How you want the system to function
- User Prompt
- What do you want to generate in reference to the system prompt
- Model
- Which model do you want to use
- Websearch
- Do you want websearch enabled
- Search_context_size
- Depending on how involved the prompt, you will want to set this to high or specify the value in tokens
- Temperature
- A value of 0 means you want ChatGPT to be purely deterministic and only generate results based on empirical data
- A value of 1 means you want ChatGPT to be incredibly creative in answers and theorize answers in ways that may not be supported by empirical data
- You can set any value in between to fine-tune
- Max_output_tokens
- This value essentially determines output length. At the moment, the maximum number of tokens supported is 128,000 which would translate roughly into 96,000 words (1 token roughly equals 0.75 words)
- Top_p
- Similar to temperature, when the model is outputting the next word, do you want it to focus only on the most common words or focus on less frequent combinations. 0 means you want more predictable output … 1 means more creative responses.
- You can set any value between 0 and 1 to fine tune output
- Store
- A true value means you want to have the conversations available in your dashboard
- A false value means you don’t want to keep the conversations